컨볼루션 신경망(CNN)은 어떤 이미지를 CNN에 입력시켜주면,
그 이미지가 개인지 고양이인지 분류해내는 목적으로 사용되어왔습니다.
기존 신경망의 경우 이미지 픽셀값들을 그대로 입력받아서 어떤 클래스에 속하는지 분류했습니다.
하지만 같은 고양이 이미지라도 살짝 회전되어 있거나, 크기가 다르거나, 변형이 조금만 생겨도 분류하는데 어려움이 있었으며, 그런 경우에 대한 훈련데이터가 모두 필요했고, 그만큼 훈련시간도 상당히 길어진다는 단점이 있었습니다.
그래서 이미지 픽셀값들을 그대로 입력받는 것보다는 이미지를 대표할 수 있는 특성들을 도출해서 신경망에 넣어주는 것이 선호되었습니다. CNN은 입력된 이미지로부터 이미지의 고유한 특징을 부각한feature map 을 새로 생성하여, 그 feature map으로 신경망에 입력되어 이미지가 어떤 클래스 라벨에 속하는지 분류합니다. 그래서 CNN에 사용되는 신경망은 분류 신경망으로 불리기도 합니다. 정리하자면, CNN은 특성 추출 신경망과 분류 신경망을 직렬로 연결한 구조로 되어 있다고 말할 수 있습니다.
2. CNN 구조

CNN은 간단한 순서
input image size
3개의 Convolution layer
2개의 Sub-sampling layer (pooling)
1개의 fully connected layer
output image size
CNN 구조 설명
input image : (1, 32, 32)
C1 layer : 입력 이미지(32, 32) 6개의 5*5 필터와 Convolution 연산을 한다. 결과 값은 6장의 28*28 피쳐맵을 만든다.
S2 layer : 2*2 필터, stride 2로 설정하여 pooling 작업을 하여 절반 크기로 축소한다. 6장의 14*14 피쳐맵을 만든다
C3 layer : 6장의 14*14 피쳐맵에 Convolution 연산을 수행하여, 16장의 10*10 피쳐맵을 만든다.
S4 layer : 2*2 필터, stride 2로 설정하여 pooling 작업을 하여 절반 크기로 축소한다. 16장의 5*5 피쳐맵을 만든다
C5 layer : 16개의 5*5 이미지를 받아 5*5 필터로 Convolution을 수행하여 1*1 크기의 피쳐맵을 만든다
F6 layer : Fully Connect 로 평탄화(차원 감소) 작업을 한다.
output image : 소프트맥스로 이미지를 분류한다.
개인적으로 구조와 순서를 처음부터 이해하기 어려워서, 위에 CNN에서 사용하는 용어를 아래에 정리했습니다. 더 확실하게 이해하기 위해 pytorch 로 LeNet-5 코드도 아래에 있습니다.
3. CNN 용어 정리
Kernel_size (Filter)
아래 그림 1차원의 32*32 이미지가 있고, 3*3 Kernel_size(Filter)를 적용하면,

위의 그림은 32 * 32 = 1024 픽셀의 형태의 이미지입니다.
여기서 3*3 필터를 사용한다는 것은 아래 그림처럼 필터가 좌우로 움직이면서 이미지를 압축한다고 할 수 있습니다.

Stride
위에서 좌우로 움직이면서 필터를 적용한다고 했는데, 이동 범위(보폭?)을 조정할 수 있습니다.
위의 그림에서는 Stride = 1 이 적용하여 1칸씩 이동했는데, 2로 변경하면 2칸씩 이동하면서 필터가 적용됩니다.
Convolution
Filter, Stride 과정을 거쳐서 이미지의 피처맵이 생성되는 과정을 Convolution 했다라고 표현합니다.
Activation Function (활성화 함수)
활성화 함수란 어떠한 신호를 입력받아 이를 적절한 처리를 하여 출력해주는 함수입니다.
이를 통해 출력된 신호가 다음 단계에서 활성화 되는지를 결정합니다.
아래 그림은 활성화 함수의 개념을 표현한 식입니다.
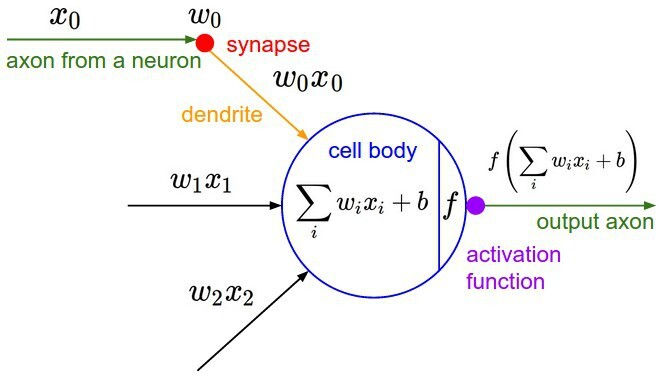
어떠한 임계값을 기준으로 활성화 되거나 혹은 비활성화 되는 형태인데,
활성화 함수에는 여러 가지 종류가 있습니다.
가장 기본이 되는 Step Function은 계단과 같이 생겼습니다.
0을 기준으로 출력이 0이거나 혹은 1로 표현되는 함수 입니다.

위의 함수 이외의 Sigmoid, ReLu, tanh 등이 있습니다.
Pooling
CNN에서 합성곱 계층과 Sigmoid와 같은 비선형 활성 함수를 거쳐서 생성된 이미지는 풀링 계층에 입력됩니다. 풀링 계층은 주로 max-pooling을 기반으로 구현된다. 아래의 그림은 스트라이드가 2로 설정된 max-pooling 기반 풀링 계층의 동작을 보여줍니다.
풀링은 행렬의 max 값만 남기고 나머지는 삭제하여 행렬 수를 줄여주는 역할을 합니다.

Fully-Connected-layer (완전연결 계층)
"완전 연결되었다"는 뜻은 한층(layer)의 모든 뉴런이 그다음 층(layer)의 모든 뉴런과 연결된 상태를 말합니다. 32 * 32 형태의 이미지를 1차원 배열의 형태로 평탄화된 행렬을 통해 이미지를 분류하는 데 사용됩니다. 32 * 32 = 1024 픽셀을 평탄화(차원 감소)하여 모든 뉴런에 전달하는 것입니다.

Soft-Max
뉴런의 출력 값에 대하여 class 분류를 위하여 마지막 단계에서 출력값에 대한 정규화를 해주는 함수입니다.
동물 사진을 예로 들어 보겠다.
사진 속 동물이 지금 개, 고양이, 토끼인지 확률적으로 수치화한다고 했을 때,
개 (11%), 고양이 (29%), 토끼(60%)와 같이 확률적 classification 을 할 때 용이합니다.
그리고 소프트맥스 함수의 특징은 결과물 수치의 합은 항상 1.0 입니다.
예제 코드를 보면..
import numpy as np
import pandas as pd
a = np.random.uniform(low=0.0, high=10.0, size=3)
def softmax(arr):
m = np.argmax(arr)
arr = arr - m
arr = np.exp(arr)
return arr / np.sum(arr)
y = softmax(a)결과 값
y
array([0.40425513, 0.02291779, 0.57282709])
y.sum()
1.04. Pytorch로 LeNet-5 (CNN) 구현하기
흔히 사용하는 숫자 mnist 파일로 LeNet-5(CNN)을 Pytorch로 구현 하겠습니다.
1. mnist 파일 로드 및 cuda 사용 확인
from torchvision import transforms
from torchvision import datasets # # MNIST training dataset 불러오기
from torch.utils.data import DataLoader
from torchvision import utils
import matplotlib.pyplot as plt
import numpy as np
import torch
# transformation 정의하기
data_transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
])
# 데이터를 저장할 경로 설정
path_data = '/DL_ALL'
# training data 불러오기
train_data = datasets.MNIST(path_data, train=True, download=True, transform=data_transform)
# MNIST test dataset 불러오기
val_data = datasets.MNIST(path_data, train=False, download=True, transform=data_transform)
# cuda 사용 가능 확인
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
print(device)
2. 불러온 데이터 shape 및 이미지 확인
# training data를 추출합니다.
x_train, y_train = train_data.data, train_data.targets
# val data를 추출합니다.
x_val, y_val = val_data.data, val_data.targets
# 차원을 추가하여 B*C*H*W 가 되도록 합니다.
if len(x_train.shape) == 3:
x_train = x_train.unsqueeze(1)
print(x_train.shape)
if len(x_val.shape) == 3:
x_val = x_val.unsqueeze(1)
# tensor를 image로 변경하는 함수를 정의합니다.
def show(img):
# tensor를 numpy array로 변경합니다.
npimg = img.numpy()
# C*H*W를 H*W*C로 변경합니다.
npimg_tr = npimg.transpose((1,2,0))
plt.imshow(npimg_tr, interpolation='nearest')
# images grid를 생성하고 출력합니다.
# 총 40개 이미지, 행당 8개 이미지를 출력합니다.
x_grid = utils.make_grid(x_train[:40], nrow=8, padding=2)
show(x_grid)실행 결과

3. Pytorch 로 모델 만들기
from torch import nn
import torch.nn.functional as F
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1) # in_channels, out_channels
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1)
self.conv3 = nn.Conv2d(16, 120, kernel_size=5, stride=1)
self.fc1 = nn.Linear(120, 84)
self.fc2 = nn.Linear(84, 10)
def forward(self, x):
print('x_0 = ',x.shape)
x = F.tanh(self.conv1(x))
print('x_1 = ',x.shape)
x = F.avg_pool2d(x, 2, 2)
print('x_2 = ',x.shape)
x = F.tanh(self.conv2(x))
print('x_3 = ',x.shape)
x = F.avg_pool2d(x, 2, 2)
print('x_4 = ',x.shape)
x = F.tanh(self.conv3(x))
print('x_5 = ',x.shape)
x = x.view(-1, 120)
print('x_6 = ',x.shape)
x = F.tanh(self.fc1(x))
print('x_7 = ',x.shape)
x = self.fc2(x)
print('x_8 = ',x.shape)
return F.softmax(x, dim=1)
model = LeNet_5()
print(model)
# 모델을 cuda로 전달
model.to(device)
print(next(model.parameters()).device)
# 모델 summary를 확인
from torchsummary import summary
summary(model, input_size=(1, 32, 32))실행 결과

처음 input size 는 (1, 32, 32) 이며,
summary 에서 Param이 뜻하는 것은 weight 와 bias 수 입니다.
아래 그림처럼 LeNet-5 모델에 따라서 순서대로 출력된 결과 입니다.
위에서 CNN 구조를 설명드린 순서와 같이 코드도 같습니다.
LeNet-5 모델로 mnist 을 학습하는 전체 코드는 아래 github에 공유 하겠습니다.
Comments